Recently, I was a participant at TagMe- an image categorization competition conducted by Microsoft and Indian Institute of Science, Bangalore. The problem statement was to classify a set of given images into five classes: faces, shoes, flowers, buildings and vehicles. As it goes, it is not a trivial problem to solve. So, I decided to attempt my existing bag-of-words algorithm on that. It worked to an extent, I got an accuracy of 86% approximately with SIFT features and an RBF SVM for classification. In order to improve my score though, I decided to look at better methods of feature quantization. I had been looking at VLAD (Vector of Locally Aggregated Descriptors): A first order extension to BoW for my Leaf Recognition project.
So, I decided to attempt to use VLAD using OpenCV and implemented a small function based on the BoW API currently in OpenCV for VLAD. The results showed remarkable improvement with an accuracy of 96.5 % using SURF descriptors on teh validation dataset provided by the organizers.
What is VLAD
Recalling BoW, it involved simply counting the no. of descriptors associated with each cluster in a codebook(vocabulary) and creating a histogram for each set of descriptors from an image, thus representing the information in a an image in a compact vector. VLAD is an extension of this concept. We accumulate the residual of each descriptor with respect to its assigned cluster. In simpler terms, we match a descriptor to its closest cluster, then for each cluster, we store the sum of the differences of the descriptors assigned to the cluster and the centroid of the cluster. Let us have a look at the math behind VLAD..
Mathematical Formulation
As with bag of words, we first train a codebook from the descriptors from our training dataset, as 



The idea behind VLAD feature quantization is that, for each cluster centroid, 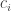


Representing the VLAD vector for each image by 

where 

The vector 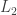

Comparison with BoW
The primary advantage of VLAD over BoW is that we add more discriminative property in our feature vector by adding the difference of each descriptor from the mean in its voronoi cell. This first order statistic adds more information in our feature vector and hence gives us better discrimination for our classifier. This also points us to other improvements we can adding higher order statistics to our feature encoding as well as looking at soft assignment,i,e. assigning each descriptor multiple centroids weighed by their distance from the descriptor.
Experiments
Here are a few of my results on the TagMe dataset.

Improvements to VLAD:
There are several extension possible for VLAD, primarily various normalization options. Arandjelov and Zissermann in their paper, All about VLAD, propose several normalization techniques, including intra normalization and power normalization alonging with a spatial extension – MultiVLAD. Delhumeau et al, propose several different normalization techniques as well as a modification to the VLAD pipeline to show improvements to almost state of the art.
Other references also stress on spatial pooling i.e. dividing your image into regions to get multiple VLAD vectors for each tile to better represent local features and spatial structure. A few also advise soft assignment, which refers to assignment of descriptors to multiple clusters, weighed by their distance from the cluster.
Code:
Here is a link to my code for TagMe. It was a quick has job for testing so it is not very clean though I am going to clean it up soon.
https://github.com/ameya005/VLAD-Implementation
also, a few references for those who want to read the papers I referred:
Well, that concludes this post. Be on the lookout for more on image retrieval – improvements to VLAD and Fisher Vectors.






