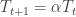Hey guys,
As I had promised, this post will be about using the Ant algorithms I had discussed in the previous post to solve a complex computational problem. But, before we go on, let us have a look again at Ant Colony optimization.
Ant Colony Optimization is basically a group of algorithms used to find optimum paths in a graph. It does so by mimicking the foraging behavior of an ant colony. As I had said before, ants use pheromones to communicate and thus the amount of pheromone on each path decides the optimality of the path. Thus, an ant is more likely to take a path with more pheromones on it. We use this concept and basically create ‘Agents’ that we call ‘Ants’. Each Ant is placed at a node and is the allowed to traverse the graph. At the end of it’s tour, we calculate the amount of pheromone on each edge of the path and then assign a probability value to it based on the amount of pheromone and the ‘visibility’ of the next node. Thus, by using a no. of ants and allowing them to traverse the graph repeatedly, we get the optimum path. Thus, we actually mimic the co-operative nature of ants in a colony to solve optimization problems.
Now, lets move on to the problem at hand. As the title suggests, today, we are going to solve one of the most famous an computationally complex problems in computer science – The Traveling Salesman Problem. The Traveling Salesman problem is modeled in the following way:
There are N cities randomly placed on a map. A salesman has to visit each city and return to the starting point such that he visits each city only once. The problem is to find the shortest path given pairwise distances between the cities.
This problem was first formulated in 1930 and is one of the most intensively studied problems in computer science and optimization. The problem is NP hard in nature. We will discuss NP hard and other such classifications in a future post. It has got several exact and heuristic solutions, so problems with large numbers of cities can be solved. Ant colony Algorithm is one of the methods of finding a solution.
The following source code has been mostly sourced from M.Tim Jones’ AI Application Programming (1st Edition) by Dreamtech. I have made slight modifications to the code and also written a python script for visualizing the problem.
Let us start with the code: ( The code is an adaptation the sourcecode found in Ch. 4 – Ant Algorithms of AI Application Programming, 1st edition by M.Tim Jones. )
Let us first define the parameters required for the Ant Colony Algorithms.
#define MAX_CITIES 30 #define MAX_DIST 100 #define MAX_TOUR (MAX_CITIES * MAX_DIST) #define MAX_ANTS 30
MAX_CITIES refers to the maximum number of cities that we have on the map. We also define the maximum pairwise distance between the cities to be 100. Thus, worst case scenario, modeled by MAX_TOUR represents the tour in which the ant has to travel through MAX_CITIES*MAX_DIST. Here, we also define the no. of ants to be 30 i.e. exactly equal to the no. of cities on the map. It has been determined experimentally that having the no. of ants equal to the no. of cities gives the optimum solution in less time than having more ants in the system.
Now, we create the environment fro the Traveling Salesman Problem (TSP).
//Initial Definiton of the problem
struct cityType{
int x,y;
};
struct antType{
int curCity, nextCity, pathIndex;
int tabu[MAX_CITIES];
int path[MAX_CITIES];
double tourLength;
};
Here, we have defined a struct cityType which contains the members – x and y. These represent the co-ordinates of the location of the city. We follow this by defining the struct antType which contains the members necessary for an ant to function. The integer values of curCity and nextCity represent the indices of the current city and the next city to be visited on the graph. The array, tabu refers to the list of cities already traversed by an Ant whereas path[] stores the path through which the Ant has traveled. The value tourLength is the distance through which the ant has traveled as of the tour.
Now that we have set up the basic setup of the problem as well as created the ants required for simulation, we will move on to defining the parameters by which the algorithm will converge to a solution.
#define ALPHA 1.0 #define BETA 5.0 //This parameter raises the weight of distance over pheromone #define RHO 0.5 //Evapouration rate #define QVAL 100 #define MAX_TOURS 20 #define MAX_TIME (MAX_TOURS * MAX_CITIES) #define INIT_PHER (1.0/MAX_CITIES)
The parameters, ALPHA and BETA are the exponents of the heuristic functions defining the pheromone deposition on the edges. ALPHA represents the importance of the trail whereas BETA defines the relative importance of visibility. Visibility here is modeled by the inverse of distance between two nodes. RHO represents the factor which defines the evaporation rate of the pheromones on the edges. QVAL is the constant used in the formula

We also declare the no. of maximum tours that the ant undertakes as 20. We also have declared a maximum time constraint in case the algorithm is not able to converge to a solution. We then weigh the edges with pheromones with the value of (1/MAX_CITIES).
//runtime Structures and global variables cityType cities[MAX_CITIES]; antType ants[MAX_ANTS]; double dist[MAX_CITIES][MAX_CITIES]; double phero[MAX_CITIES][MAX_CITIES]; double best=(double)MAX_TOUR; int bestIndex;
Now, we declare an array of cityType structs which will contain be defining the nodes of our graph. We also create an array of Ants with the size equal to that of cities. The double dimensional array dist records the pairwise distances between the cities whereas the array phero records the pheromone levels on each edge between the cities. The variable best is used as a control variable for recording the best tour after every iteration.
void init()
{
int from,to,ant;
//creating cities
for(from = 0; from < MAX_CITIES; from++)
{
//randomly place cities
cities[from].x = rand()%MAX_DIST;
cities[from].y = rand()%MAX_DIST;
//printf("\n %d %d",cities[from].x, cities[from].y);
for(to=0;to<MAX_CITIES;to++)
{
dist[from][to] = 0.0;
phero[from][to] = INIT_PHER;
}
}
//computing distance
for(from = 0; from < MAX_CITIES; from++)
{
for( to =0; to < MAX_CITIES; to++)
{
if(to!=from && dist[from][to]==0.0)
{
int xd = pow( abs(cities[from].x - cities[to].x), 2);
int yd = pow( abs(cities[from].y - cities[to].y), 2);
dist[from][to] = sqrt(xd + yd);
dist[to][from] = dist[from][to];
}
}
}
//initializing the ANTs
to = 0;
for( ant = 0; ant < MAX_ANTS; ant++)
{
if(to == MAX_CITIES)
to=0;
ants[ant].curCity = to++;
for(from = 0; from < MAX_CITIES; from++)
{
ants[ant].tabu[from] = 0;
ants[ant].path[from] = -1;
}
ants[ant].pathIndex = 1;
ants[ant].path[0] = ants[ant].curCity;
ants[ant].nextCity = -1;
ants[ant].tourLength = 0;
//loading first city into tabu list
ants[ant].tabu[ants[ant].curCity] =1;
}
}
The above snippet of code is used to initialize the entire graph and the Ants that we are going to use to traverse the graph. We basically allot random co-ordinates to the cities and then compute the pairwise distances between them. Also, we initialize the ants with an Ant on each node of the graph. We also initialize the rest of the properties of each Ant including the tabu list and the path. The next part of the algorithm is to restart the ants after each traversal by returning them to their original positions.
//reinitialize all ants and redistribute them
void restartAnts()
{
int ant,i,to=0;
for(ant = 0; ant<MAX_ANTS; ant++)
{
if(ants[ant].tourLength < best)
{
best = ants[ant].tourLength;
bestIndex = ant;
}
ants[ant].nextCity = -1;
ants[ant].tourLength = 0.0;
for(i=0;i<MAX_CITIES;i++)
{
ants[ant].tabu[i] = 0;
ants[ant].path[i] = -1;
}
if(to == MAX_CITIES)
to=0;
ants[ant].curCity = to++;
ants[ant].pathIndex = 1;
ants[ant].path[0] = ants[ant].curCity;
ants[ant].tabu[ants[ant].curCity] = 1;
}
}
We also store the best path and the value of the best path in the global variables that we have defined.
double antProduct(int from, int to)
{
return(( pow( phero[from][to], ALPHA) * pow( (1.0/ dist[from][to]), BETA)));
}
int selectNextCity( int ant )
{
int from, to;
double denom = 0.0;
from=ants[ant].curCity;
for(to=0;to<MAX_CITIES;to++) { if(ants[ant].tabu[to] == 0) { denom += antProduct( from, to ); } } assert(denom != 0.0); do { double p; to++; if(to >= MAX_CITIES)
to=0;
if(ants[ant].tabu[to] == 0)
{
p = antProduct(from,to)/denom;
//printf("\n%lf %lf", (double)rand()/RAND_MAX,p);
double x = ((double)rand()/RAND_MAX);
if(x < p)
{
//printf("%lf %lf Yo!",p,x);
break;
}
}
}while(1);
return to;
}
This set of functions is used in the process of selecting the next edge to traverse. Each ant in the environment selects the next edge in accordance with the equation discussed in the last post. Here we have a simple reciprocal function of distance as a measure of visibility as well as the actual value of the pheromone itself as the function to represent pheromone. There has been extensive research in this domain such that these functions may be replaced by other suitable heuristic functions. For the simple TSP that we are going to solve, the functions thatwe use prove to be a good enough measure.
Now comes the actual process of simulating an ant colony. The following function is an example of simulating the ant colony to solve the TSP.
int simulateAnts()
{
int k;
int moving = 0;
for(k=0; k<MAX_ANTS; k++)
{
//checking if there are any more cities to visit
if( ants[k].pathIndex < MAX_CITIES ) { ants[k].nextCity = selectNextCity(k); ants[k].tabu[ants[k].nextCity] = 1; ants[k].path[ants[k].pathIndex++] = ants[k].nextCity; ants[k].tourLength += dist[ants[k].curCity][ants[k].nextCity]; //handle last case->last city to first
if(ants[k].pathIndex == MAX_CITIES)
{
ants[k].tourLength += dist[ants[k].path[MAX_CITIES -1]][ants[k].path[0]];
}
ants[k].curCity = ants[k].nextCity;
moving++;
}
}
return moving;
}
//Updating trails
void updateTrails()
{
int from,to,i,ant;
//Pheromone Evaporation
for(from=0; from<MAX_CITIES;from++)
{
for(to=0;to<MAX_CITIES;to++)
{
if(from!=to)
{
phero[from][to] *=( 1.0 - RHO);
if(phero[from][to]<0.0)
{
phero[from][to] = INIT_PHER;
}
}
}
}
//Add new pheromone to the trails
for(ant=0;ant<MAX_ANTS;ant++)
{
for(i=0;i<MAX_CITIES;i++)
{
if( i < MAX_CITIES-1 )
{
from = ants[ant].path[i];
to = ants[ant].path[i+1];
}
else
{
from = ants[ant].path[i];
to = ants[ant].path[0];
}
phero[from][to] += (QVAL/ ants[ant].tourLength);
phero[to][from] = phero[from][to];
}
}
for (from=0; from < MAX_CITIES;from++)
{
for( to=0; to<MAX_CITIES; to++)
{
phero[from][to] *= RHO;
}
}
}
The next snippet of code is simply a helper function which emits all the data into atext file so as a python script can present it in a better and easily understandable form.
void emitDataFile(int bestIndex)
{
ofstream f1;
f1.open("Data.txt");
antType antBest;
antBest = ants[bestIndex];
//f1<<antBest.curCity<<" "<<antBest.tourLength<<"\n";
int i;
for(i=0;i<MAX_CITIES;i++)
{
f1<<antBest.path[i]<<" ";
}
f1.close();
f1.open("city_data.txt");
for(i=0;i<MAX_CITIES;i++)
{
f1<<cities[i].x<<" "<<cities[i].y<<"\n";
}
f1.close();
}
Now let us move on to the main()
int main()
{
int curTime = 0;
cout<<"MaxTime="<<MAX_TIME;
srand(time(NULL));
init();
while( curTime++ < MAX_TIME)
{
if( simulateAnts() == 0)
{
updateTrails();
if(curTime != MAX_TIME)
restartAnts();
cout<<"\nTime is "<<curTime<<"("<<best<<")";
}
}
cout<<"\nBest tour = "<<best<<endl;
emitDataFile(bestIndex);
return 0;
}
Here we simply run the simulations and keep on updating trails and restarting the simulation with the updated trails until the no. of iterations does not exceed MAX_TIME. This ensures thatthe simulation terminates regardless of whether the ANT agents converge onto a solution or not after a set no. of iterations.
This is the primary code for the Ant Algorithm solution for the Traveling Salesman Problem in C++. Now, I have written a small python script which plots the data using matplotlib and creates a beautiful graph for us to view.
from numpy import *
import matplotlib.pyplot as plt
def city_read():
x,y=loadtxt('city_data.txt', unpack = True)
order=loadtxt('Data.txt')
print order
print x
print y
'''order1[]
x1[]
y1[]'''
x1=[]
y1=[]
for i in order:
x1.append(x[i])
y1.append(y[i])
x1.append(x[order[0]])
y1.append(y[order[0]])
plt.plot(x1,y1, marker='x', linestyle = '--', color = 'r')
for i in range(len(order)):
plt.text(x1[i],y1[i],order[i])
plt.show()
def main():
city_read()
if __name__=="__main__":
main()
The script outputs an easy to read graph which pinpoints the cities on a graph and highlights the optimum path as outputted by the ant algorithm. Here are a few output images:

A solved TSP

ANTs plot out a path

Output for a randomly generated city map
P.S.: You can find the above code as well as several other implementations at my git:
https://github.com/ameya005/AntColonyAlgorithms

 is the intensity of pheromone on the edge between the nodes r and u.
is the intensity of pheromone on the edge between the nodes r and u.  is the weight for the pheromone, and
is the weight for the pheromone, and 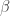 is the weight for the distance of the edge which can be modeled after visibility.
is the weight for the distance of the edge which can be modeled after visibility. 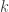 is the no. of edges not traversed yet. This formula can be said to be the ratio of the weight of an edge to the sum of the weights of all untraveled edges. Thus, this will give us a probability based on the amount of pheromone deposited and the distance of the edge. Both of these values will help us in converging to an optimal value.
is the no. of edges not traversed yet. This formula can be said to be the ratio of the weight of an edge to the sum of the weights of all untraveled edges. Thus, this will give us a probability based on the amount of pheromone deposited and the distance of the edge. Both of these values will help us in converging to an optimal value.
 is a constant and
is a constant and  is the total length of the tour. We then use this value to calculate the total pheromone value due to a single ant after a tour.
is the total length of the tour. We then use this value to calculate the total pheromone value due to a single ant after a tour.
 is a constant between 0 and 1.
is a constant between 0 and 1.